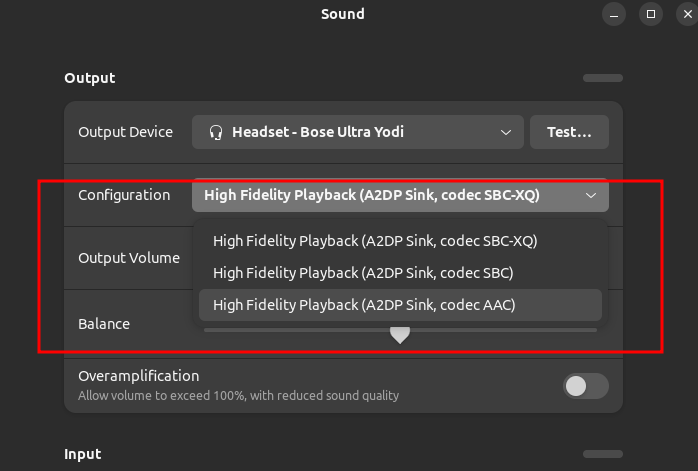
I’m using Bose QuietComfort Ultra and its have capabilities to support multiple codecs. Connecting into Ubuntu, currently its only support for SBC-XQ and SBC. To unlock the lossless compression on AAC in Ubuntu 24.04 we need to do several things
- Install pipewire with AAC patch
- Switch from PulseAudio to Pipewire
- Enable it from the sound configuration
Lets do it
First, enable this PPA https://launchpad.net/%7Eaglasgall/+archive/ubuntu/pipewire-extra-bt-codecs
sudo add-apt-repository ppa:aglasgall/pipewire-extra-bt-codecs
sudo apt updateThen, re-install pipewire
sudo apt remove pulseaudio-module-bluetoothsudo apt install --reinstall pipewire-audio-client-libraries libspa-0.2-bluetooth libspa-0.2-jack pulseaudio-utilsNext, we configure it
sudo apt install pipewire-audio-client-libraries
sudo apt install pipewire-media-session- wireplumber
systemctl --user --now enable wireplumber.service
sudo apt install libldacbt-{abr,enc}2 libspa-0.2-bluetooth pulseaudio-module-bluetooth-sudo cp /usr/share/doc/pipewire/examples/ld.so.conf.d/pipewire-jack-*.conf /etc/ld.so.conf.d/
sudo ldconfigFollow the PPA gist : https://gist.github.com/the-spyke/2de98b22ff4f978ebf0650c90e82027e#gistcomment-4320194
Now enable and verify
systemctl --user --now enable wireplumber.service
pactl infoServer String: /run/user/1000/pulse/native
Library Protocol Version: 35
Server Protocol Version: 35
....
Server Name: PulseAudio (on PipeWire 1.0.5) <------ HERE
Server Version: 15.0.0
Default Sample Specification: float32le 2ch 48000Hz
Default Channel Map: front-left,front-right
Default Sink: bluez_output.AC_BF_71_CF_15_96.1
Default Source: alsa_input.usb-If Bluetooth re-connection has problem like its rejected or stop working after connected at fresh start, this is the solution
First un-pair the device then
sudo systemctl stop bluetooth
sudo rm -rf /var/lib/bluetooth/*
sudo systemctl start bluetooth
sudo rebootPair it again. Voila Done!